Officially Microsoft SQL Server 2019 is only available for Ubuntu 16.04 (Xenial) if you read the documentation: https://docs.microsoft.com/nl-nl/sql/linux/quickstart-install-connect-ubuntu?view=sql-server-linux-ver15
Some blogs are saying that the preview can be run on Ubuntu 18.04 as you see here: https://bornsql.ca/blog/does-sql-server-2019-run-on-ubuntu-18-04-lts/
We’re a bit further in time now and SQL Server 2019 is GA and CU3 is all ready released. I’m still wondering that it is still not supported since I did find repositories for older and newer Ubuntu distributions there. Probably I was a bit ahead in time with this post because I found a new article saying that 18.04 is really supported since CU3 and in the meantime CU4 is released!
After installing a new Ubuntu 18.04 through the netboot.iso with the OpenSSH server enabled and the only thing you need to do is:
apt-get install open-vm-tools gnupg software-properties-common
wget -qO- https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/18.04/mssql-server-2019.list)"
apt-get update
apt-get install -y mssql-server
/opt/mssql/bin/mssql-conf setup
systemctl status mssql-server --no-pagerThe detailed output of the setup command:
root@sql03:~# /opt/mssql/bin/mssql-conf setup
usermod: no changes
Choose an edition of SQL Server:
1) Evaluation (free, no production use rights, 180-day limit)
2) Developer (free, no production use rights)
3) Express (free)
4) Web (PAID)
5) Standard (PAID)
6) Enterprise (PAID) - CPU Core utilization restricted to 20 physical/40 hyperthreaded
7) Enterprise Core (PAID) - CPU Core utilization up to Operating System Maximum
8) I bought a license through a retail sales channel and have a product key to enter.
Details about editions can be found at
https://go.microsoft.com/fwlink/?LinkId=2109348&clcid=0x409
Use of PAID editions of this software requires separate licensing through a
Microsoft Volume Licensing program.
By choosing a PAID edition, you are verifying that you have the appropriate
number of licenses in place to install and run this software.
Enter your edition(1-8): 5
The license terms for this product can be found in
/usr/share/doc/mssql-server or downloaded from:
https://go.microsoft.com/fwlink/?LinkId=2104294&clcid=0x409
The privacy statement can be viewed at:
https://go.microsoft.com/fwlink/?LinkId=853010&clcid=0x409
Do you accept the license terms? [Yes/No]:Yes
Enter the SQL Server system administrator password:
Confirm the SQL Server system administrator password:
Configuring SQL Server...
The licensing PID was successfully processed. The new edition is [Standard Edition].
ForceFlush is enabled for this instance.
ForceFlush feature is enabled for log durability.
Created symlink /etc/systemd/system/multi-user.target.wants/mssql-server.service → /lib/systemd/system/mssql-server.service.
Setup has completed successfully. SQL Server is now starting.
root@sql03:~# systemctl status mssql-server --no-pager
● mssql-server.service - Microsoft SQL Server Database Engine
Loaded: loaded (/lib/systemd/system/mssql-server.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2020-03-12 23:03:09 CET; 9s ago
Docs: https://docs.microsoft.com/en-us/sql/linux
Main PID: 3935 (sqlservr)
Tasks: 139
CGroup: /system.slice/mssql-server.service
├─3935 /opt/mssql/bin/sqlservr
└─3959 /opt/mssql/bin/sqlservr
Mar 12 23:03:13 sql03 sqlservr[3935]: [158B blob data]
Mar 12 23:03:13 sql03 sqlservr[3935]: [155B blob data]
Mar 12 23:03:13 sql03 sqlservr[3935]: [61B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [96B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [66B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [75B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [96B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [100B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [71B blob data]
Mar 12 23:03:14 sql03 sqlservr[3935]: [124B blob data]
Within minutes you’ve your Microsoft SQL Server 2019 server running with the latest update and when you connect to it with the SQL Server Management Studio and built-in SQL user:
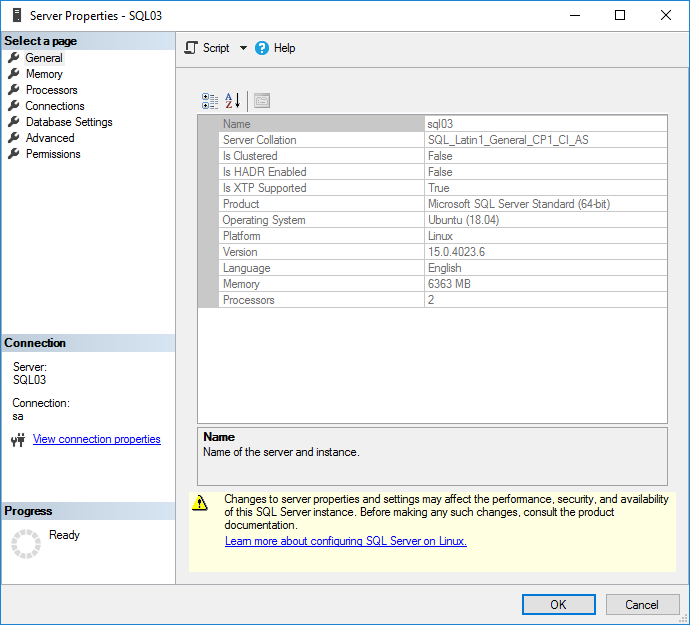
Install sqlcmd
On https://docs.microsoft.com/nl-nl/sql/linux/sql-server-linux-setup-tools?view=sql-server-linux- you can see that the sqlcmd for 18.04 is officially there… Odd! You can install it like:
apt install curl
curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list | sudo tee /etc/apt/sources.list.d/msprod.list
apt-get update
apt-get install mssql-tools unixodbc-dev
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profileAfter re-login you can execute a query through sqlcmd:
root@sql03:~# sqlcmd -S localhost -U SA -Q 'select @@VERSION'
Password:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Microsoft SQL Server 2019 (RTM-CU3) (KB4538853) - 15.0.4023.6 (X64)
Mar 4 2020 00:59:26
Copyright (C) 2019 Microsoft Corporation
Standard Edition (64-bit) on Linux (Ubuntu 18.04.4 LTS) <X64>
(1 rows affected)